
이번에는 집합 ADT입니다.
먼저 특징을 살펴보자면, 집합 ADT는 유일한 개체들을 담아야 하고 이러한 개체들을 정렬된 리스트로 표현한다는 것이 되겠습니다.
각 개체들은 유일해야 하고, a b c d 나 1 2 3 4처럼 정렬되어야 합니다.
이런 집합 ADT의 주요 함수들은 이렇습니다.
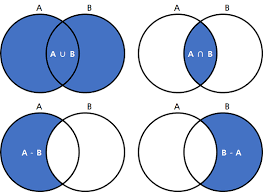
set union(B)
set intersect(B)
set subtract(B)
union은 집합 B와 합집합을 반환하고,
intersect는 집합 B와 교집합을 반환합니다. 그리고
subtract는 집합 B를 차감한 차집합을 반환합니다.
그리고 이러한 메서드들의 실행시간은 최대 O(|A| + |B|)가 되어야 합니다. 즉, 각 집합들의 최대 원소들의 수를 합한 것이 최대 실행시간이 된다는 것입니다.
이외의 함수들도 써놓겠습니다.
//일반 함수
int size()
bool isEmpty()
iter elements()
//질의 함수
bool member(e)
bool subset(B)
//갱신 함수
addElem(e)
removeElem(e)
이러한 집합을 응용하면
- 직접 응용 : 키워드 검색엔진이나 집합론에 대한 다양한 계산을 수행할 수 있습니다.
- 간접 응용 : 보조 데이터 구조를 설계할 수 있습니다.
구현
집합 ADT는 보통 연결 리스트의 형태로 구현할 수 있습니다.
(BUT, 배열로도 충분히 구현할 수 있습니다.)
따라서 각 노드들의 하나의 집합 원소를 표현합니다.
이제 집합 함수를 보여드리기 전에 하나 알려드릴 것이 있는데
집합 함수들은 "파괴적"인 케이스와 "비파괴적"인 케이스로 나뉩니다.
따라서 파괴적인 경우에는 함수를 실행시키고 나서 집합 A와 B는 보존되지 않고 비파괴적인 경우에는 함수를 실행시키고 나서 집합 A, B가 보존될 수 있습니다.
합집합
List unionList(List* A, List* B) //합집합
{
List C;
initList(&C);
int a, b;
while (!isEmpty(A) && !isEmpty(B))
{
a = getfirst(A);
b = getfirst(B);
if (a < b)
{
addListelem(&C, a);
removeListelem(A);
}
else if (a > b)
{
addListelem(&C, b);
removeListelem(B);
}
else //a == b
{
addListelem(&C, a);
removeListelem(A);
removeListelem(B);
}
}
while (!isEmpty(A))
{
a = getfirst(A);
addListelem(&C, a);
removeListelem(A);
}
while (!isEmpty(B))
{
b = getfirst(B);
addListelem(&C, b);
removeListelem(B);
}
return C;
}우선 첫 번째 while문을 통해서 A와 B 둘 중에 하나라도 빌 때까지 계속 반복합니다.
변수 a, b를 통해서 각 리스트들의 첫 번째 원소를 받아오고 조건문을 통해서 서로 비교합니다.
이게 집합 List다 보니까
- 각 원소들은 유일해야 하고
- 정렬되어있어야 합니다. 그것이 오름차순이든 내림차순이든.
따라서 저희는 입력할 때부터 오름차순으로 했으니까 오름차순으로 값들을 List C에 저장하기 위해서 두 a, b사이에서 더 작은 값을 찾습니다. 그리고 더 작은 값이 있다면 그것을 List C에 추가합니다. 그리고 a가 들어갔다면 A List의 첫 번째 노드를 삭제하고 b가 들어갔다면 B List의 첫 번째 노드를 삭제합니다. a와 b가 같을 때도 그 값을 추가하고 A List, B List의 첫 번째 노드를 삭제합니다.
이것을 반복하면서 만약에 A나 B리스트에서 비어있는 리스트가 존재한다면 반복문을 탈출합니다.
이후 A와 B리스트에 남아있는 원소들은 유일하므로 모두 C List에 넣어줍니다.
교집합
List intersectList(List* A, List* B) //교집합
{
List C;
initList(&C);
int a, b;
while (!isEmpty(A) && !isEmpty(B))
{
a = getfirst(A);
b = getfirst(B);
if (a < b)
{
removeListelem(A);
}
else if (a > b)
{
removeListelem(B);
}
else //a == b
{
addListelem(&C, a);
removeListelem(A);
removeListelem(B);
}
}
while (!isEmpty(A))
removeListelem(A);
while (!isEmpty(B))
removeListelem(B);
return C;
}교집합은 좀 쉬운데 교집합은 두 집합 사이에서 겹치는 똑같은 것만 뽑는 거잖아요?
그러니 a == b 일 때만 C List에 원소를 추가합니다.
차집합
List subtractList(List* A, List* B) //차집합
{
List C;
initList(&C);
int a, b;
while (!isEmpty(A) && !isEmpty(B))
{
a = getfirst(A);
b = getfirst(B);
if (a < b)
{
addListelem(&C, a);
removeListelem(A);
}
else if (a > b)
{
removeListelem(B);
}
else //a == b
{
removeListelem(A);
removeListelem(B);
}
}
while (!isEmpty(A))
{
a = getfirst(A);
addListelem(&C, a);
removeListelem(A);
}
while (!isEmpty(B))
removeListelem(B);
return C;
}차집합을 구하는 것이므로 순수한 A를 뽑아내면 됩니다.
따라서 a < b일 때나 while(!isEmpty(A))부분에서 순수한 A를 뽑을 수 있습니다.
전체 코드
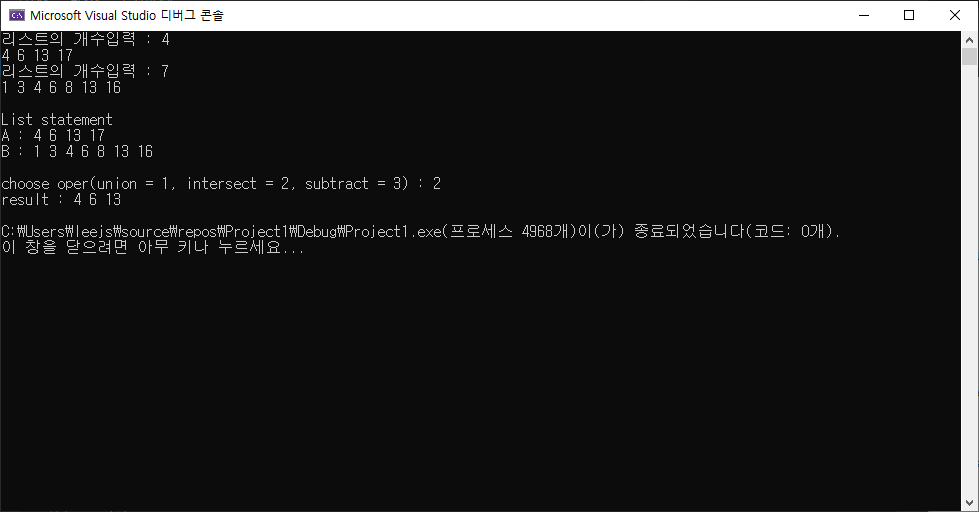
결과 화면


끝 마치며..... 각 A, B를 파괴하지 않으면서 집합 연산을 할 수 없을까 하는 생각이 드실 겁니다.
비파괴적인 집합 연산은 재귀적으로 해결할 수 있는데요. 글이 길어지니 다음에 쓰도록 하겠습니다. ㅎㅎ bye~